11 Dec 2021
About
The Elbert V2 is an entry level FPGA board manufactured by Numato Lab. It has a
Xilinx Spartan 3a FPGA, and 16 Mb SPI flash memory. This blog is about how to
generate (“synthesize”) bitstream for it and how to program the bitstream to it,
in Linux.
Install Xilinx ISE Webpack on Linux
The Xilinx ISE Webpack is the official (and only?) tool to generate bitstream
for Xilinx FPGAs. The download and installation process is a full of roadblocks
and in great lack of documentation, but in the end the Linux version worked out
pretty well for me. The tool is free, though to download you need first create
an account with Xilinx and get a free license (that lasts a year?). Then the
installation package is composed of four individual tarballs, each is about 2GB
in size. Extract the first one, ending with .tar, a file called xsetup will
be present in the root directory, which is the installer. Run it and it’ll
guide you through the installation process. The installation is relatively
painless, except… that when the installation completes, the wizards simply
exists, leaving you wondering where the heck the program had been installed to.
Towards the end of the installation, it’ll ask you an installation location,
though at that location the installer will create a deep chain of directories
and dozens of files. The final program, ISE, is at
$INSTALL_DIR/14.7/ISE_DS/ISE/bin/lin64/ise (14.7 is the version of the ISE
webpack installed so yours may be different, and lin64 is the 64-bit version;
there is a 32-bit version too). One more thing you need to be aware, is that
before invoking that program, you’ll need to source a shell script installed
at $INSTALL_DIR/14.7/ISE_DS/settings64.sh (again, note the version and
64-bit).
Once you’ve worked around all that, the actual ISE program is nicely designed,
runs pretty smoothly. You can create projects, loading existing projects,
generating bitstreams, etc.
Programming Elbert V2 SPI Flash
The Elbert V2 can be connected to a Linux PC via USB, and the standard CDC_ACM
Linux kernel module will create a pseudo tty device, e.g., /dev/ttyACM0 for
connected Elbert V2. To program a bitstream file (with the file
extension .bin) to the Elbert V2, there is a python script provided by Numato
Lab:
https://github.com/numato/samplecode/blob/master/FPGA/ElbertV2/tools/configuration/python/elbertconfig.py. The only thing to note here is the need to have the pyserial library, otherwise programming works like a charm: python elbertconfig.py /dev/ttyACM0 <bistream-file.bin>.
04 Dec 2021
Workaround Ubuntu’s “blank screen” boot failure
In my experience this not unique to Ubuntu (Fedora, ArchLinux also had a similar problem), but after a fresh install of Ubuntu on the NUC, if you reboot, your NUC will flash the “Intel NUC” BIOS screen for a quick second and go blank indefinitely. Power cycling doesn’t seem to help. The fix is to append nomodeset to the kernel command line.
To do this, plug in a USB stick with a bootable image. Reboot and select the bootable image from the USB stick. Select “Try Ubuntu” instead of “Install Ubuntu” so you won’t wipe out the image already installed on your hard drive/SSD. Once booted into the live CD, open a shell, and mount the EFI and rootfs partitions of the on-disk OS:
$ mkdir root boot
$ sudo mount /dev/sda1 boot
$ sudo mount /dev/sda2 root
$ sudo vi root/boot/grub/grub.cfg
# Append 'nomodeset' to the kernel command line
$ sudo umount root
$ sudo umount boot
$ sudo reboot
NOTE: here I’m editing the file in the rootfs partition because the “root” GRUB
config that lives in the EFI partitions simply sources the one in the rootfs
partition. So always start with the one in the EFI partition because that’s
what the BIOS will load.
Unplug the USB stick, reboot, and you should be able to see the boot continue as usual.
Use a desktop switch to connect your NUC and your primary desktop computer for faster file transfers
The NUC comes with a wifi interface which is convenient for connecting to the
Internet. But for data transfer between the NUC and your primary desktop, it’s
best to use an Ethernet switch for more bandwidth and less variability. When I
did this I saw a 100x increase in bandwidth:
[I] ~> iperf -c 192.168.86.31 (wifi endpoint)
------------------------------------------------------------
Client connecting to 192.168.86.31, TCP port 5001
TCP window size: 129 KByte (default)
------------------------------------------------------------
[ 1] local 192.168.86.250 port 53639 connected with 192.168.86.31 port 5001
[ ID] Interval Transfer Bandwidth
[ 1] 0.00-10.19 sec 12.1 MBytes 9.98 Mbits/sec
[I] ~> iperf -c 192.168.5.31 (ethernet endpoint)
------------------------------------------------------------
Client connecting to 192.168.5.31, TCP port 5001
TCP window size: 129 KByte (default)
------------------------------------------------------------
[ 1] local 192.168.5.32 port 53640 connected with 192.168.5.31 port 5001
[ ID] Interval Transfer Bandwidth
[ 1] 0.00-10.04 sec 1.10 GBytes 940 Mbits/sec
Use X11 forwarding to run GUI applications from your primary desktop
If you are using the NUC in a headless configuration (i.e., no monitor
connected), and yet need to run some GUI application from time to time, X11
forwarding over SSH could be a good option. For MacOS, there is XQuartz. After
installing XQuartz, run ssh nuc -Y (-X most likely will also work) and you
will get an SSH session with X11 forward. If you then type, e.g., firefox, in
the terminal, a firefox window will be started on your MacOS.
I am not yet sure if this is better than VNC but in my experience VNC gave me a
gray screen with no content - could be a mistake on my end but I didn’t invest
further.
03 Oct 2020
Suppose you are to write a C function that compares two uint64_t numbers. The
function is supposed to return a negative number if the first argument compares
less than the second, zero if they compare equal, or a positive number if the
first is greater. Sounds pretty familiar, right? Many C library functions
takes a “comparator” function pointer that does that. While it sounds trivial,
there is a subtle gotcha that is worth writing a blog post about.
It is tempting to writing a trivial comparator like this.
int compare1(uint64_t a, uint64_t b) {
return a - b;
}
While it looks pretty neat, and seemingly satisfies the requirement, it is
vulnerable to a common pitfall when it comes to arithmetics of large numbers:
overflow! To demonstrate the problem with this implementation, let’s look at
the following sample program:
#include <inttypes.h>
#include <stdint.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
uint64_t a = 0;
uint64_t b = UINT64_MAX;
printf("a - b (as uint64_t) = %" PRIu64 "\n", a - b);
printf("a - b (as int64_t) = %" PRIi64 "\n", (int64_t)(a - b));
printf("a - b (as delta of int64_t's) = %" PRId64 "\n",
(int64_t)a - (int64_t)b);
return 0;
}
What do you think the output of the three printf statements would be?
~$ clang -c source.c && ./a.out
a - b (as int64_t) = 1
a - b (as uint64_t) = 1
a - b (as delta of int64_t's) = 1
~$
All three would print a positive 1, even though a (0) is clearly smaller than
b (UINT64_MAX). It is because 0 - UINT64_MAX overflows the range of 64
bit integers and wraps around to become 1. As you can see, casting the result
or a and b individually to signed numbers don’t help because UINT64_MAX is
already larger than INT64_MAX. If a and b were 32 bit numbers and you had
a 64 bit machine you could try up-casting them to 64 bit numbers to avoid the
overflow problem, but for 64 bit numbers that trick doesn’t work any more.
So what is the fix? Well, don’t try to be smart to do subtractions. Use plain
old comparisons:
int compare2(uint64_t a, uint64_t b) {
if (a < b) return -1;
if (a > b) return 1;
return 0;
}
For those that understand a little bit of assembly may wonder, doesn’t
comparisons boil down to subtractions eventually since cmp src dst
instructions basically subtracts dst from src any way? While that’s true,
the hardware is kind enough to have a flag register which keeps track of
overflows in arithmetic operations. In this case, since we are dealing with
unsigned integer overflows, the carry flag will be set if we tried to cmp 0
UINT64_MAX. On the other hand, the compiler is smart enough to read this flag
after a cmp instruction, and will use an “overflow aware” jump instruction
like jae (jump if the first operand of the previous cmp instruction is above
or equal to its second operand, taking into consideration the carry flag) to
always get the correct comparison result.
This is evident in the compiler generated assembly code for the above two
comparator implementations (generated with clang -S source.c):
.p2align 4, 0x90 ## -- Begin function compare1
_compare1: ## @compare1
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq %rdi, -8(%rbp)
movq %rsi, -16(%rbp)
movq -8(%rbp), %rax
subq -16(%rbp), %rax
## kill: def $eax killed $eax killed $rax
popq %rbp
retq
.cfi_endproc
## -- End function
.p2align 4, 0x90 ## -- Begin function compare2
_compare2: ## @compare2
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq %rdi, -16(%rbp)
movq %rsi, -24(%rbp)
movq -16(%rbp), %rax
cmpq -24(%rbp), %rax
jae LBB2_2 <===== Notice the use of JAE here
## %bb.1:
movl $-1, -4(%rbp)
jmp LBB2_5
LBB2_2:
movq -16(%rbp), %rax
cmpq -24(%rbp), %rax
jbe LBB2_4
## %bb.3:
movl $1, -4(%rbp)
jmp LBB2_5
LBB2_4:
movl $0, -4(%rbp)
LBB2_5:
movl -4(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
19 Jul 2020
These three tools seem to have a great deal of overlapping functionalities. All
have built-in regular expression matching, and many grep functionalities can
be replicated by sed and awk. For example, if I have a file, test.txt,
with the content:
NE 1 I
TWO 2 II
#START
THREE:3:III
FOUR:4:IV
FIVE:5:V
#STOP
SIX 6 VI
SEVEN 7 VII
And if I want to print the lines that don’t have the keywords “START” or “STOP”
in them, I could do:
grep -vE "START|STOP" test.txt
Or:
sed -nr '/START|STOP/ !p' test.txt
Or:
awk '$0 !~ /START|STOP/' test.txt
Having used all, my rules of thumb for picking the right tool to use for a task
are:
grep is for search only-
sed if for search and replace. The underscore is on ed, for editing.
You start with a regular expression matching to find the text you want to
edit on, and take an action on the matching (or non-matching) text. The
possible actions are:
- substitute, with the
s/<pattern>/<substitue>/ command
- delete, with the
d command
- or simply print, with the
p command
awk’s unique power is in processing columns or fields in the matching
lines of text. Suppose you have a table of data. You could first use pattern
matching to select the rows you want to operate on, and then use awk’s
powerful column matching to process each column - printing, modifying,
skipping, etc.
Of course I could separate the search from the editing and column processing, by
using grep for the search and piping its output to sed or awk, but
sometimes it’s nicer to have them all done with one command.
14 Apr 2020
Design Netflix
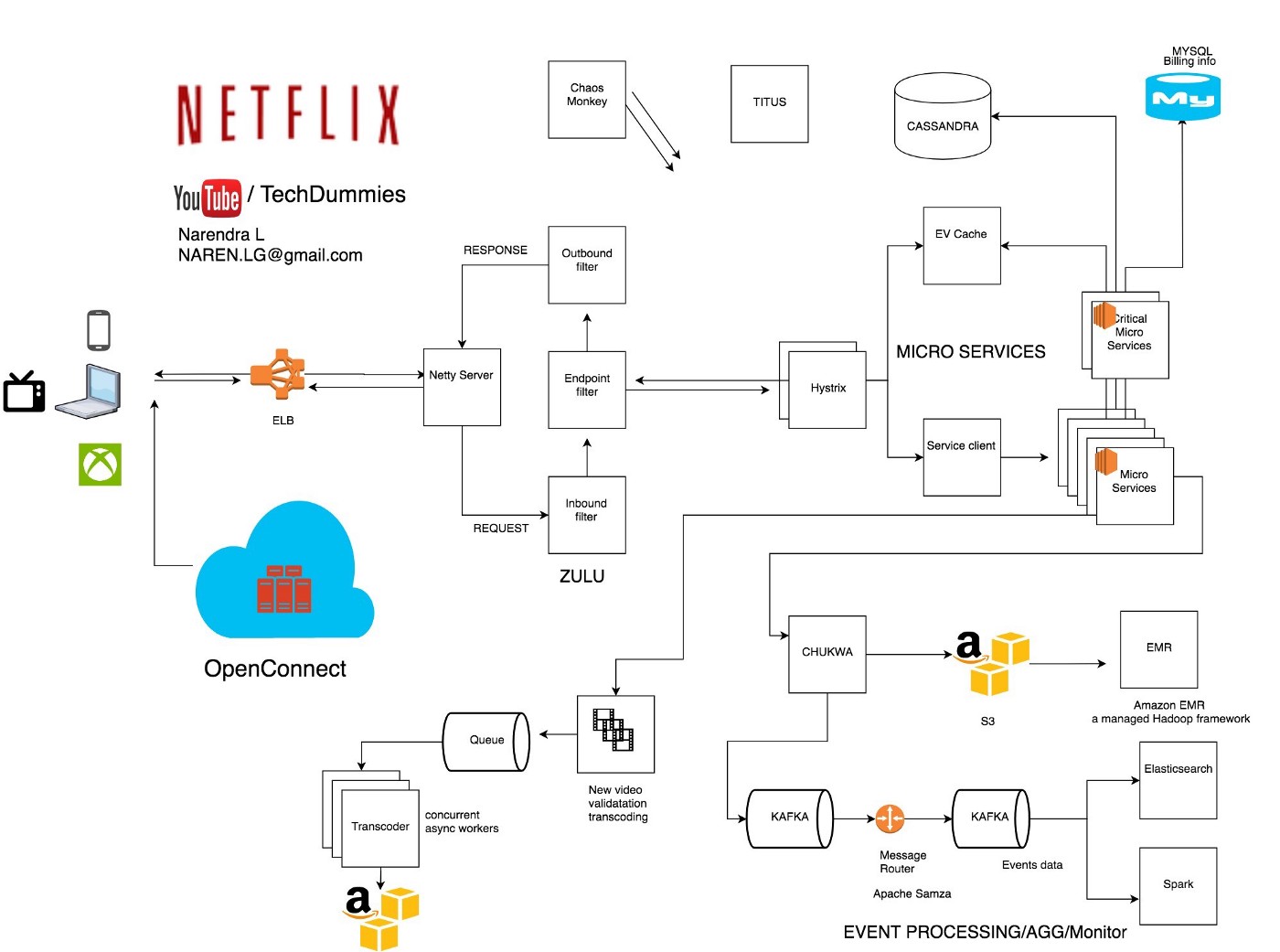
From https://medium.com/@narengowda/netflix-system-design-dbec30fede8d.
Notes
Video transcoding. For example, H.265 –> MP4. May change resolution and frame
rate to better user experience on a particular device.
Netflix also creates difference video files depending on the network speeds you
have. On average, 1200 files are created for one video.
Once a video is transcoded, the thousands of copies of it get pushed to the many
streaming servers that Netflix has, via its Content Dellivery Network
(CDN).
When a user clicks the play button on a video, a nearby streaming server is
matched, for the video copy with the best resolution and framerate for the
user’s device.
Content recommendation. Netflix uses data mining (Hadoop) and machine learning
to recommend videos the user might enjoy watching based on their browse / view
history.
Client side. Netflix supports 2200 different devices: Android, iOS, gaming
consoles, web apps, etc, involving various client side technology. On the
website, they use React JS a lot, for its startup speed, runtime performance and
modularity.
Front end load balancing. User requests are routed to Netflix’s frontends via
AWS’s Elastic Load Balancer, which is the two tier load balancer. At the first
tier, it uses DNS based round robin to select an ELB endpoint in a particular
“zone”. At the second tier, it does another round robin to select a server
within that zone.
EV Cache. A distributed key value store based on Memcached. Reads are served by
the nearest server, or a backup server if the nearest is down. Writes are
duplicated to all servers. SSDs are used for persistent yet performance storage.
Database. Static data like user profiles and billing information are stored in
MySql databases. Netflix runs its own MySql deployment on EC2 VMs. Handles
database replication and etc. Replicate fail-over is done via updating a DNS
entry for the DB host.
Cassandra. A distributed wide column NoSQL data store. Designed for consistent
read/write performance at scale. Netflix stores user viewing history in
Cassandra. Latest view history that undergos frequent reads and writes are
stored uncompressed while older history is compressed, to save storage.
Monitoring and event processing. The Netflix’s clients generate a lot of events
every second of every day: ~500 billion events per day (~1.3 PB data) and ~8
million events and ~24GB data to be processed per second during peak hours.
Events include video viewing activities, UI activities, error logs, and etc.
They use Apache Chukwa to collect and monitor these events. Chukwa is based on
HDFS and Map Reduce. The collected events are routed by Kafka to various data
sinks: S3, Elastic Search, and possibly a secondary Kafka.
Netflix uses Elastic Search to help with mapping a user end failure (failure to
watch a video) to error logs. Elastic Search is a document search engine. AWS
has a managed version of it.
Autoscaling. When people get home from work, load increases and the system
automatically scales up.
Media processing. Switching gears a bit, over to the content production side.
Before a video is put on the Netflix site, it undergos a lot of processing
steps. For instance, large videos are split and encoded in chunks, in parallel.
Spark. Content recommendation and personalization is done via managed Spark
clusters.